Rust异步2: Future模型
上一篇为什么需要异步中提到由于不确定事件使得等待无法避免, 并发是可以提供程序运行效率的一种方式. 多线程模式使用最广泛, 兼容性最后, 但由于内存占用和竞争切换等问题, 并发规模会受到线程数量的限制. 为了进一步提高并发的效率和使用体验, 很多语言都(比如Go, Erlang, C#)提供了自己的编程模型, 下面我们就开始介绍Rust的Future模型.
Future的定义
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
Future是定义在标准库中的trait(类似Java的Interface), 表示最终可以计算出一个值(包括空值())的异步任务. 定义的内容很简单, 关联类型Output是任务计算完成后返回值的类型, poll方法是任务的具体执行过程.
// poll 方法的返回类型
pub enum Poll<T> {
Ready(T) // 计算完成, 返回T类型的值
Pending // 还没完成, 需要继续推进
}
poll方法的返回值Poll是枚举类型, 有两种情况, 一种是Ready(T), 表示任务计算完成, 返回一个T类型的值; 另一种是Pending, 表示任务暂时停滞, 后面需要继续推进.
pub struct Context<'a> {
waker: &'a Waker,
local_waker: &'a LocalWaker,
}
第一个入参Pin表示Future在内存中的位置是"固定"的, 涉及到自指结构的内存安全问题, (Pin和自指类型)[https://dlzht.github.io/007-rust-yi-bu-04/]这篇会单独介绍; 第二个入参Context是Future运行的上下文, 现在Context里只有waker相关字段, 用来唤醒任务, 使得可以继续向前推进.
Future的运行过程
正如前面文章里描述的, 由于不确定的事件, "等待"无法避免. 在多线程模式下, 阻塞的是线程, 操作系统会调度其他线程到CPU上执行. 等到事件准备就绪了, 阻塞的线程变成就绪状态. 等下次再被操作系统调度到时, 通过线程上下文切换继续执行下去.
而Future模式, 阻塞的是任务(task, future), 系统线程并不阻塞. 运行时(runtime)会调度其他的任务到线程上执行. 等到事件准备就绪了, 阻塞的任务变成就绪状态. 等下次再被运行时调度到时, poll方法再次被运行时调用.
| 多线程模式 | Future模式 | |
|---|---|---|
| 谁调度控制 | 操作系统 | runtime |
| 阻塞的粒度 | 系统线程 | 任务(Future, Task) |
| 继续的方式 | 上下文切换 | 调用poll方法 |
| 关注的资源 | CPU | 系统线程 |
Future模式根据不确定事件, 把任务分割成一个个子过程, 执行完一个子过程后直接返回Pending, 然后陷入等待. 后续等待的事件就绪了, 再被调度继续执行后一个子过程. 就这样一步步向前推进, 最终任务计算完成, 返回计算结果Ready(T).
假如说现在有个任务fut是休眠1秒后返回一个数字, 那fut任务会在休眠这个点被分割成两部分, 运行过程大概是这样:
- fut被运行时调度到线程上执行, 即runtime调用fut的poll方法
- fut执行休眠操作(不阻塞线程), 返回Pending, 线程执行权回到运行时
- 运行时调度其他的任务到线程上执行, 而fut在1秒后被唤醒变成就绪
- fut再次被调度到线程上, poll方法被运行时调用, 最终返回一个数字
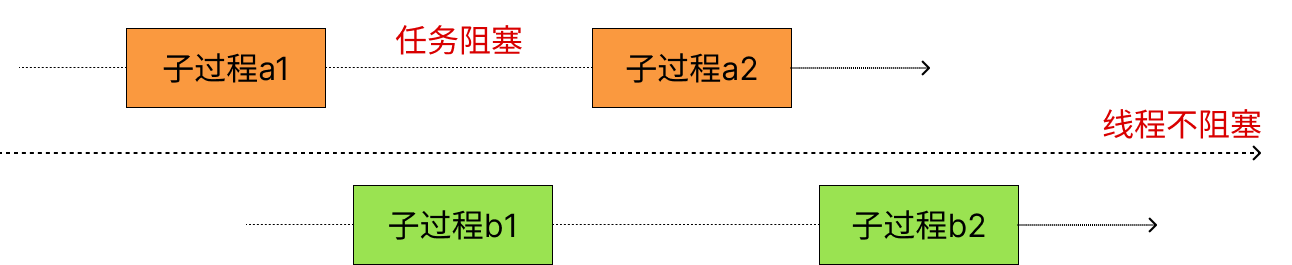
一方面, 任务遇到需要等待的事件时, 会把执行的机会让给其他任务, 就可以让计算机充分地运作起来; 另一方面, 阻塞的是任务而不是线程, 所以不需要很多线程就可以处理大量任务, 就可以避免系统线程带来的开销.
Future的工作原理
运行时调度任务运行就是调用Future的poll方法, 没有特别的魔法, 所以Future要能够按照上面的方式工作, 那么poll的实现要解决以下几个问题:
- 如何能在不阻塞线程的情况下调用网络或者文件这些操作
- 在任务需要等待时, 怎么把线程的执行权返回给运行时
- 在等待的事件就绪时, 怎么唤醒任务, 后续才能继续调度
- 运行时推进任务时都是调用poll, 怎么实现"继续"执行
// 保存任务的状态
enum NumFuture { Step0, Step1 }
impl Future for NumFuture {
type Output = i32;
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
// 不同状态的跳转分支
return match *self {
NumFuture::Step0 => {
let waker = cx.waker().clone();
// 异步调用
std::thread::spawn(move || {
std::thread::sleep(Duration::from_secs(1));
// 唤醒埋点
waker.wake();
});
// 状态变更
*self = NumFuture::Step1;
// 返回未完成状态
Poll::Pending
}
NumFuture::Step1 => {
// 返回最终结果
Poll::Ready(0)
}
}
}
}
上面的NumFuture实现了休眠1秒后返回数字0, 结合这段代码和注释我们来说明poll的实现是如何解决上面这些问题的.
- 非阻塞调用: 这边是用开启另一个线程的方式实现了不阻塞当前线程, 更通常的我们会使用第三方库提供的非阻塞方法. 这些方法不会阻塞当前线程, 可能使用了系统的异步调用, 也可能是运用了线程池技术.
- return返回: 运行时推动任务的方式是调用Future的poll方法, 和其他的函数调用的过程没有区别, 所以通过return语句, Future就可以把执行权交还给运行时. 任务还没完成, 就return Pending, 执行结束了, 就return Ready(T).
- 唤醒埋点: poll方法的入参Context里包含唤醒器waker, 而唤醒器的wake方法可以"唤醒"Future, 告诉运行时这个任务又可以被调度了. 所以poll方法中, 在适当的地方(直接或者间接)调用waker方法, 后续这个Future就可以被再次调度执行了.
- 状态变更: 操作系统的线程实现继续执行, 需要记住指令执行到哪, 数据是什么, Future也是一样. 一方面, poll根据某个字段(这边是Step0, Step1)跳转到不同的代码分支, 这就相对于记住了代码执行到哪; 另一方面, 将后续执行需要的数据也保存起来, 比如Step1(0), 这样就相当于记住了数据是什么. Future一边向前执行, 一边更新自己的状态, 就可以实现"继续"的语义.
Future的推动执行
就像上面描述的, Future不会阻塞线程, 在需要等待时会把执行权还给运行时, 所以对CPU的利用效率很高, 运行时只要不断地调用就绪Future的poll方法就可以了, 而waker唤醒器则需要告诉运行时哪些Future变成就绪了, 运行时和唤醒器的伪代码实现大致如下:
// runtime不断执行就绪的Future
while let Some(fut) = ready_futs.next() {
fut.poll( ... );
}
// waker把Future推入ready_futs
ready_futs.push(fut);
tokio是一个第三方的异步运行时, 具体实现要精巧复杂得多, 不过工作原理大差不差. 这边我们可以用tokio提供的运行时来执行NumFuture, 最终计算出的结果res是0.
fn main() {
// 创建runtime
let rt = tokio::runtime::Builder::new_current_thread().build().unwrap();
// 创建异步任务
let fut = NumFuture::Step0;
// 把任务交给运行时
let res = rt.block_on(fut);
}
Future的一些特点
- 协作式: 推进任务时, 运行时调用任务的poll方法, 线程执行权从运行时转移到任务; 任务需要等待事件或者执行完成时, 通过return返回Poll, 线程执行权从任务转移到运行时. 运行时和任务之间是平等的, 互相协作交替在线程上运行. 不像操作系统与线程之间的调度是命令式的, 操作系统可以剥夺线程在CPU上的运行.
- 状态机: 为了实现"继续"执行, Future需要保存指令和数据信息. 而编译器转换async函数时生成的匿名Future, 会把这些信息作为状态字段保存在Future实例中, Future逐步推进, 这些状态也逐步更新, 所以说Future是用状态机实现的.
- 无栈: 这里说的栈类似于线程的"运行栈", 线程在被调度的时候, 寄存器相关的信息会保存在栈中, 这样才能实现线程的"继续"执行(上下文切换). 而Futurer让出执行的点是确定的, 需要保存哪些信息在编译时就可以确定, 所以用的是状态机而不是运行栈. 相比于运行栈, 状态机的大小是确定的, 所以Future可以"完美"利用内存, 但这也导致Future不能被动让出执行, 如果有需要长时间执行的任务的话, 可能会出现饥饿问题.