译文: Go是怎么处理栈的
这是一篇翻译文章, 原文是How Stacks are Handled in Go(by Daniel Morsing). 这篇文章向我们介绍了Go解决协程栈增长问题的两种方式和他们的优缺点, 可以帮助我们了解异步模型中有栈还是无栈(Rust的Future是无栈)的考虑出发点.
One of the more important features of Go is goroutines. They are cheap, cooperatively scheduled threads of execution that are used for a variety of operations, like timeouts, generators and racing multiple backends against each other. To make goroutines suitable for as many tasks as possible, we have to make sure that each goroutine takes up the least amount of memory, but also have people be able to start them up with a minimal amount of configuration.
To achieve this, Go manages stacks in way that behaves like any other language, but is quite different in how they're implemented.
轻量级协程goroutines是Go的一大特点, 被广泛应用于超时, 生成器和多端竞争等等场景. 让每个协程尽可能少地占用内存, 是goroutine能胜任海量并发的关键, 但同时也要考虑是否只要少量的配置就能开始使用.
为了兼顾运行效率和使用体验, Go管理栈的方式虽然看上去和其他语言差不多, 但底层的实现却是截然不同的.
An introduction to thread stacks
Before we look at Go, let's look at how stacks are managed in a traditional language like C.
When you start up a thread in C, the standard library is responsible for allocating a block of memory to be used as that thread's stack. It will allocate this block, tell the kernel where it is and let the kernel handle the execution of the thread. The problem comes when this block of memory is not enough.
在讲述Go之前, 我们可以先来看下老派的C是如何管理栈的.
当我们在C里开启一个线程时, 标准库会分配一块内存作为这个线程的运行栈. 然后把栈的位置告诉内核, 内核就可以在这个栈上运行线程了. 我们这篇文章要讨论的问题就是"这块"内存不够的时候怎么办, 或者说栈增长的问题.
Consider the following function:
int a(int m, int n) { if (m == 0) { return n + 1; } else if (m > 0 && n == 0) { return a(m - 1, 1); } else { return a(m - 1, a(m, n - 1)); } }This function is highly recursive and invoking it as a(4,5) will consume all of the stack memory. To get around this, you can adjust the size of blocks that the standard library hands out to thread stacks. However, increasing your stack size across the board means that every thread will take up that amount of memory, even if they're not highly recursive. You can run out of memory, even though your program isn't using the stack memory allocated.
The other option is to decide stack size on a per thread basis. Now you're tasked with having to configure how much stack memory each thread needs, which makes creating a thread more difficult than we want it to be. Figuring out how much memory a thread will take is in the general case undecidable and in the common case just very difficult.
考虑这段递归代码, 如果调用a(4, 5)的话, 就会导致栈溢出. 虽然我们可以调整标准库创建的栈的大小, 但并不是只有当前线程会被影响, 其他线程也会分配到更多的栈内存, 哪怕这些内存并不会被用到. 用这个方式, 甚至可以在栈内存还没开始使用前, 就耗尽所有的内存空间.
另一个可选的方式是分别调整每个线程的栈内存, 但这就需要我们配置这个栈到底是多大, 无疑增加了线程的使用复杂度. 通常来说线程会使用多少内存是不确定的, 要计算分配多少内存是非常困难的.
How Go handles this
Instead of giving each goroutine a fixed amount of stack memory, the Go runtime attempts to give goroutines the stack space they need on demand, freeing the programmer from having to make decisions about stack size. The Go team is currently working on switching from one method to another for doing this. I'll try to explain the old method, its shortcomings, the new method and why we're switching to it.
Go没有采用分配固定大小的栈内存的策略, 而是尝试给每个协程按需分配内存, 开发者也不需要考虑栈的大小. 具体怎么实现这个按需分配, Go团队正在从一种实现方式迁移到另一种实现方式, 下文将会介绍原有的方式是怎么实现的, 有什么缺点, 新的方式又是什么, 以及为什么要切换到新的方式.
Segmented stacks
Segmented stacks is the original way that Go handled stacks. When a goroutine is created, we allocate an 8 kilobyte section of memory to use for the stack and we let the goroutine run its course.
The interesting bit comes when we run out of stack space for these 8 kilobytes. To handle this, each Go function has a tiny prologue at function entry. It checks if we've used up the allocated stack space and calls the morestack function if we have.
The morestack function allocates a new section of memory for stack space. It then fills in various pieces of data about the stack into a struct at the bottom of the stack, including the address of the stack that we just came from. After we've got a new stack segment, we restart the goroutine by retrying the function that caused us to run out of stack. This is known as a stack split.
Go原有的处理栈增长问题的方式是分段栈, 当创建一个协程时, 会分配一个8KB的栈先用着.
每个Go函数前都有一个检查当前栈内存是否用完的"小片段", 当这8KB的栈用完后, 有趣的事情就发生了, 这时会会进入到morestack函数.
morestack会给栈空间再分配一段新的内存, 然后将一些相关信息, 包括之前栈的地址, 都保存在这新栈中. 在分配完新段后, 协程就会重新调用这个触发栈溢出的函数, 协程就可以继续运行下去了. 这样的实现方式就叫做分段栈.
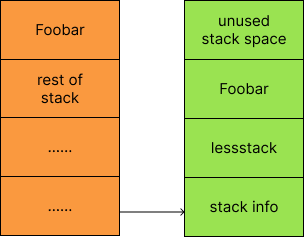
The stack looks like this just after we've split the stack.
At the bottom of the new stack, we've inserted a stack entry for a function called lessstack. We didn't actually call this function. It is set up for when we return from the function that caused us to run out of stack. When that happeyou we return into the lessstack, it looks up the struct that we put at the bottom of the stack and adjusts the stack pointer so that we're returning into the previous segment. After this, we can deallocate the stack segment we came from and go on our way.
分段栈的内存布局如上图所示. 可以看到在新栈的底部, 有一部分是给lessstack函数的, 和morestack一样, lessstack并不是我们直接调用的. 在导致栈溢出的函数返回后, 就会进入到lessstack, 而lessstack会找到栈底的相关信息, 然后调整栈指针, 这样就可以返回到前一段栈里了, 而不再使用的新段也可以回收掉了.
The problem with segmented stacks
Segmented stacks give us stacks that grow and shrink on demand. The programmer doesn't have to worry about sizing the stacks, starting a new goroutine is cheap and we're now handling the case where the programmer doesn't know how big the stack will grow.
This was how Go handled stack growing up until recently, but this approach had a flaw. Shrinking the stack is a relatively expensive operation. It was most felt when you had a stack split inside a loop. A function would grow, split the stack, return and deallocate the stack segment. If you're doing this in a loop, you end up paying a rather large penalty.
This was known as the hot split problem. It was the main reason that the Go developers switched over to a new method of managing stacks, called stack copying.
分段栈可以按照实际需要分配或者回收栈段, 开发者也不需要考虑该设置多大的栈, 虽然开启新的协程的开销很小, 但开发者并不知道这个栈会增长到多大.
之前的Go就是用分段栈的方式来解决栈增长问题的, 但这个方式有缺陷, 那就是回收栈的开销比较大. 如果在一个循环里碰到了栈溢出, 那么在调用时会分配栈段, 在返回时又会回收栈段, 那这个问题就会尤为明显, 面临的开销将比较巨大.
这个问题叫做'hot split', 正是因为这个问题, Go的开发者选择了转向新的管理栈的方式, 栈复制.
Stack copying
Stack copying starts out a lot like segmented stacks. The goroutine is running along, using the stack space and when it runs out, it hits the same stack overflow check as in the old approach.
However, instead of having a link back to the previous segment, it creates the new segment with double the size and copies the old segment into it. This means that when the stack shrinks back to its old size, the runtime doesn't have to do anything. Shrinking is now a free operation. Additionally, when the stack grows again, the runtime doesn't have to do anything. We just reuse the space that we allocated earlier.
栈复杂的方式和分段栈有一部分是相似的, 协程在运行过程中使用栈内存, 在栈内存耗尽的时候就会触发栈溢出检查.
但不是再多分配一个栈段, 栈复制是创建一个两倍大的新栈, 然后把旧栈里的数据复杂到新栈里. 在所需内存变小的时候, Go不会做什么, 因为回收内存是有开销的. 而且后面需要的内存又变大时, 这部分"多余"的内存就可以用到了.
How are stacks copied?
Copying the stack sounds easy but it is a bit of an undertaking. Since variables on the stack can have their address taken in Go, you end up in a situation where you have pointers into the stack. When you move the stack, any pointers to the stack are now going to be invalid.
Lucky for us, the only pointers that can point into the stack are pointers that live on the stack. This is necessary for memory safety since otherwise, it would be possible for a program to access parts of the stack no longer in use.
Because we need to know where the pointers are for garbage collection, we know which parts of the stack are pointers. When we move the stack, we can update the pointers within the stack to their new targets and all the relevant pointers are taken care of.
栈复制并不是看上去的那么简单, 因为在Go是允许获取栈上变量的地址的, 也就是可能有指针会指向栈上的变量, 如果栈的位置变动了, 这些指针也就失效了.
幸运的是, Go规定了指针变量和指向内容得在同一个栈上, 这一点对于内存安全很重要, 否则程序就有可能访问不再使用的栈内存了.
因为Go有垃圾回收机制, 所以我们知道栈上哪些变量是指针. 当栈发生复制移动后, 只要更新栈上所有的指针变量, 把指向的地址改成新的地址就行了.
Since we use the garbage collection information to copy stacks, any function that can show up on a stack must have this information available. This was not always the case. Because large sections of the runtime were written in C, a lot of the calls into the runtime did not have pointer information and as such weren't copyable. When this happened, we fell back to stack segments, with their associated costs.
This is why the runtime developers are currently rewriting large pieces of the runtime in Go. The code that cannot reasonably be rewritten in Go, like the core of the scheduler and the garbage collector, will get executed on special stacks which are sized individually by the runtime developers.
Besides making stack copying possible, this will also allow us to do things like concurrent garbage collection in the future.
由于栈复制依赖于垃圾回收机制, 所以在栈上运行的函数都应该提供相关信息, 但事实并不如此. Go的运行时里有很大一部分是用C写的, 所以很多运行时调用不会提供指针信息, 这些栈就无法复制, 只能使用开销较大的分段栈方式.
这也正是开发者们在用Go重写大部分运行时的原因, 类似调度器和垃圾回收器这些无法用Go重写的核心部分, 则会放到固定栈大小的特殊栈上去运行.
指针变量和指向内容得在同一个栈上, 不仅使栈复制成为可能, 也使未来的并发回收成为可能.
An aside about virtual memory
A different way of handling stacks is to allocate large sections of virtual memory. Since physical memory is only allocated when the memory is touched, it looks like you can just allocate a large section and let the operating system handle it. There are a couple of problems with this approach.
Firstly, 32-bit systems only have 4 gigabytes of virtual memory, of which normally only 3 gigabytes are available for the application. Since it is not uncommon to have a million goroutines running at once, you will likely run out of virtual memory, even if we assume that stacks are only 8 kilobyte.
Secondly, while we can allocate large amounts of memory for 64-bit systems, it relies on overcommitting memory. Overcommit is when you allocate more memory than you physically have and rely on the operating system to make sure that physical memory is allocated when it is needed. However, enabling overcommit carries some risk. Since processes can allocate more memory than the machine has, it has to make up memory somehow if the processes start actually using more memory than is available. It can do this by putting sections of memory onto disk, but this adds latency that is unpredictable and often, systems are run with overcommit turned off for this reason.
另一种解决栈增长问题的方式是虚拟内存, 因为物理内存只有在实际用到的时候才会进行分配, 所以我们可以让程序申请很大的内存, 然后把实际的内存分配交给系统去做. 这种方式也有一些缺陷.
首先, 32位的系统只有4GB的虚拟内存, 而能分配给应用的通常只有3GB. 同时运行成千上万个协程的情况是完全可能的, 所以就算每个协程只需要8KB的栈内存, 虚拟内存也会被耗尽.
其次, 虽然64位的系统能分配很大的内存, 但这依赖于'overcommitting memory'机制, 系统允许程序申请的内存超过实际物理内存的大小, 在使用到这些内存时系统再真正的去分配. 但这种方式带来了一些风险, 系统可能会用磁盘空间来替代内存, 而磁盘的速度比内存要慢, 所以会带来不可预测的延迟, 因而系统的'overcommit'通常是没有开启的.
Conclusion
A lot of effort has gone into making goroutines cheap, fast and suitable for most tasks. Stack management is just a small part of that.
为了让协程尽可能的轻量, 快速, 能适用于更多的场景, Go付出了很多努力, 栈的管理只是其中一小部分.
/br>