走马观花http库2
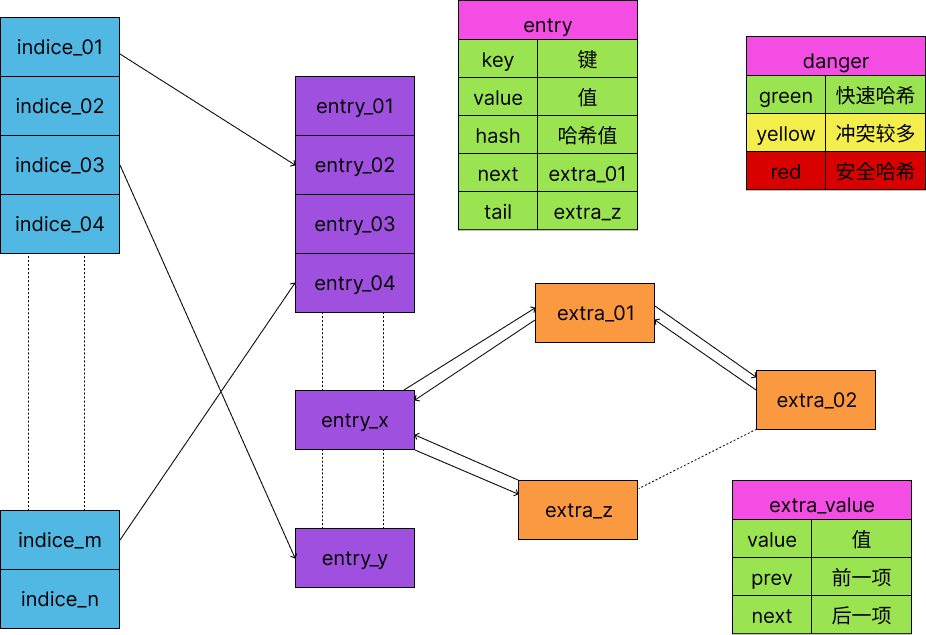
HeaderMap是http库里用来处理协议头的结构, 本质上是一个哈希表, 解决哈希冲突的策略是开放地址, 地址探测采用的是robin hood. 因为是专用于http头的场景, 还具有键不区分字母大小写, 一个键可以对于多个值, 可以在快速哈希和安全哈希间切换等特点.
数据结构
pub struct HeaderMap<T = HeaderValue> {
mask: Size,
entries: Vec<Bucket<T>>, //存放键和值
indices: Box<[Pos]>, //哈希槽
extra_values: Vec<ExtraValue<T>>, //存放多个值
danger: Danger, //安全状态
}
HeaderMap的代码定义如上, mask是一共分配了多少哈希槽, entries存放键和值, indices是哈希槽, extra_values处理一个键有多个值的情况, danger是安全状态, 用来应对哈希碰撞攻击.
entries: Vec<Bucket<T>>
struct Bucket<T> {
hash: HashValue, //哈希值
key: HeaderName, //键
value: T, //值
links: Option<Links>, //有多个值时, 双向链表表头
}
struct Links {
next: usize,
tail: usize,
}
entries数组里的元素, 即保存了键, 也保存了一个值. 如果这个键有多个值, 其他的值会用links串起来, 构成一个双向链表. hash这个字段是对键做哈希得到的哈希值, 在查找时作为比较条件的一部分.
indices: Box<[Pos]>
struct Pos {
index: Size, //在entries数组中的下标
hash: HashValue,
}
indices是哈希槽数组, 槽里的Pos记录的是entries数组的下标, 表示这个槽位的的具体数据是 entries数组里的第index项. entries和indices的比例大概是3:4, indices的最大长度被限制为1<<15.
extra_values: Vec<ExtraValue<T>>
struct ExtraValue<T> {
value: T, //值
prev: Link, //前一项
next: Link, //后一项
}
enum Link {
Entry(usize), //entries数组里的元素
Extra(usize), //extra_values数组里的元素
}
当键对应多个值时, 除第一个值会和键一起存放在entries数组中, 其余的值会存放在extra_values数组, 这些值一起串成一个双向链表, entries里的第一个值相当于表头. extra_values里的元素只保存值而不保存键, 所以和entries里的元素有一些区别, 这里Link枚举 用Entry和Extra这两种类型表示.
HeaderMap的实现可能是参考了indexmap的早期实现, 见issue 489. 用下标替代指针查找, 数据项集中存储在数组中, 更好地利用缓存局部性.
地址探测
由于HeaderMap解决哈希冲突的策略是开放地址, 所以需要地址探测来确定冲突项该放在哪个槽里, 这里采用的算法是robin hood. 当要插入一个键值对(key, value)时, 理想的槽位应该是hash(key) & mask.
如果这个槽位已经被占用了, 就顺延到下一个位置. 每顺延一次, 离理想槽位的距离就+1. 对于键x, 我们可以用d(x)表示这个距离. 如果键x正好可以放在理想位置, 那d(x)就是0.
fn try_insert2<K>(&mut self, key: K, value: T) -> Result<Option<T>, MaxSizeReached> {
//预先占位, 包含扩容, 校验是否安全等操作
self.try_reserve_one()?;
//计算键的哈希值
let hash = hash_elem_using(&self.danger, &key);
//计算理想槽位
let mut probe = desired_pos(self.mask, hash);
'probe: loop {
//循环数组
if probe < (self.indices.len()) {
//当前槽位已经被占用
if let Some((pos, entry_hash)) = self.indices[probe].resolve() {
//计算当前槽位里项的距离
let their_dist = probe_distance(self.mask, entry_hash, probe);
//当前槽位里项的距离更小
if their_dist < dist {
ret = {
self.try_insert_phase_two(key.into(), value, hash, probe, danger)?;
None
};
break 'probe;
//键已存在
} else if entry_hash == hash && self.entries[pos].key == key {
ret = (Some(self.insert_occupied(pos, value)));
break 'probe;
}
//槽位为空, 直接使用
} else {
ret = {
let index = self.entries.len();
self.try_insert_entry(hash, key.into(), value)?;
self.indices[probe] = Pos::new(index, hash);
None
};
break 'probe;
}
dist += 1;
probe += 1;
} else {
probe = 0;
}
}
Ok(ret)
对于插入(key, value), 找到合适的槽位有两种情况. 第一种, 在顺延过程中, 如果槽里有键x, 如果d(key) > d(x), 就可以占用这个槽位, 让x往后去找其他位置. 第二种, 遇到了空槽, 直接占用这个空槽就行.
查询键key时, 从理想位置开始, 逐个比较键是否相同, 直至遇到空槽或者d(x) < d(key); 删除key时, 先找到对应的槽位清理, 然后把这个槽开始到下一个空槽之间的项都往前挪一个位置.
在插入和删除时维护距离规则, 就是robin hood这种地址探测算法, 用来尽量保证查询效率的手段.
哈希安全
哈希碰撞攻击, 就是攻击者可以找到一组键, 这组键计算出来的哈希值是相同的, 所以在构造哈希表时会发生大量的冲突, 使得增删查的效率大幅下降. 安全哈希一般通过引入随机性, 使得同一个键在不同哈希表实例中, 算出来的哈希值不同.
fn hash_elem_using<K>(danger: &Danger, k: &K) -> HashValue
{
let hash = match *danger {
//红色状态使用安全哈希
Danger::Red(ref hasher) => {
let mut h = hasher.build_hasher();
...
}
//其他状态使用快速哈希
_ => {
let mut h = FnvHasher::default();
...
}
};
}
HeaderMap提供了两种方式来计算键的哈希值, 一种是FnvHasher, 算起来快但不够安全, 在一般状态时使用; 另一种是DefaultHasher, 即标准库提供的默认哈希, 算起来比较慢但安全, 在红色状态时使用.
FnvHasher对与某个键计算出来的结果总是一样的, 所以不够安全; 而DefaultHasher中有随机数, 可以避免哈希碰撞攻击. 在接收响应或者请求时, 协议头通常是外部输入参数, 引入哈希安全非常必要.
键HeaderName
let name= HeaderName::from_str("A");
println!("{:?}", name); //Ok("a")
HeaderMap哈希表键的类型是HeaderName, 根据RFC的描述, 协议头的键里如果有拉丁字母, 在HTTP1.1版本的是不区分大小写的, 在HTTP2.0版本则只能是小写. 因此在使用HeaderName::from_bytes, HeaderName::from_str等函数时, 大写会自动转换成小写, 创建出来的HeaderName不会包含大写字母.
值HeaderValue/T
从类型定义上HeaderMap<T = HeaderValue>可以看出, HeaderMap的值除了默认的HeaderValue类型, 还可以是其他类型T. 除了处理键值对形式的协议头, HeaderMap还能用来做其他事.
比如HeaderCaseMap的内部就是一个HeaderMap, 用在需要区分大小写的场景中. HeaderCaseMap的键值大概是这样HeaderName -> [Name1, name2, NAME3], 配合上HeaderMape里的HeaderName -> [v1, v2, v3], 就可以还原出最初的协议头内容了.