Pingora的超时优化
pingora-timeout上有一段注释, 显示在基准测试中, pingora处理超时事件比tokio默认的时间轮快了有40倍左右. 这倒是挺有意思的, 这篇文章就来看看pingora是怎么优化超时事件的处理的.
1. 怎么进行超时优化的
1.1 pingora是什么
pingora是由被网友们称为"互联网慈善家", "赛博活菩萨"的Cloudflare出品的, 一套用来构建快速, 可靠, 可编程网络系统的Rust框架, 23年05月在Github公开发布源代码.
根据CF的这两篇文章how-we-built-pingora-the-proxy...和pingora-open-source, 由pingora构建的HTTP代理现已在CF内服役, 每天服务的请求超过1万亿次(new!).
//! Benchmark:
//! - create 7.809622ms total, 78ns avg per iteration
//! - drop: 1.348552ms total, 13ns avg per iteration
//!
//! tokio timer:
//! - create 34.317439ms total, 343ns avg per iteration
//! - drop: 10.694154ms total, 106ns avg per iteration
文章里多次提到了快速和高效这样的字眼, 翻了一翻pingora的代码, 其中pingora-timeout模块有如上注释, 大概意思是, 新增和删除时间事件, 和tokio的时间轮(可以看我上一篇的介绍)相比, 性能提升了n倍.
看数据这提升量可不小啊, 不会是忽悠我吧? 能优化这么多, 还是说tokio还有很大提升空间啊? 实话实说, 跑了下beanch下的基准测试, 数据也没那么漂亮, 当然也可能是我操作有误...
可能注释里是CF"真实"的数据, 由实际运行中的服务得来的. 能做到这样的优化, 我觉得那是因为pingora的使用场景比较固定, 从而可以作出比tokio更激进的优化, 下文也尝试着分析下.
1.2 应用场景的特点
pingora里的时间事件主要有休眠和超时两类, 心跳检查, 错误重试, 延迟发送等会用到休眠事件; 建立连接, 读取请求, 发送响应等会用到超时事件. 在CF的HTTP代理服务里, 时间事件有如下特点:
- 事件的数量会很多, 按CF提到的1万亿请求每天, 读写分别加个超时, 就有2万亿事件了. 当然, 肯定会有很多的机器分担负载, 不过单台上的事件数量也不会少(按C10K问题来的话).
- 时间精度相对宽松, 一方面只有超时边界附件的请求会受到影响的, 相对来说是"少量"的; 另一方面, CF的代理面向全球, 纵然可能针对某些服务单独配置, 但大体上也是笼统模糊的.
- 时间范围相对确定, HTTP服务的响应要求及时, 毕竟响应每延迟X秒, 用户就流失百分之Y. 所以中间代理服务的超时时间也不用设置的太长, 可以限定在小范围的区间内(比如[0, 10]秒).
1.3 时间事件的优化
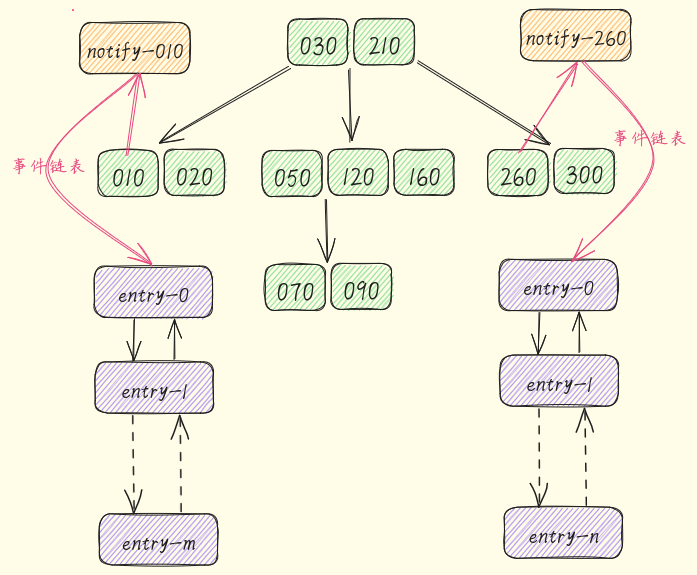
- 没有全局的锁, 每个线程的时间事件都单独管理, 维护事件的数据结构是线程本地的, 不像tokio时间轮是运行时全局的, 新增或者删除时间事件都要用锁来同步.
- 时间精度粗糙些, 每个槽位的跨度都是10毫秒, 槽位里的事件都监听在同一个Notify上.
Notify管理事件的结构也是链表, "用链表管理事件"这一点上倒是差别不大. - 使用B树维护槽位, 因为时间的跨度大致在一定范围内, 所以可以使用区间跨度都一样的槽位, 而且槽位的数量可以控制在一定范围内. 用B树实现增删和排序, 相对来说比较简单.
1.4 与运行时的协作
- 在tokio里, 维护时间事件的是时间轮, 时间轮会把最近就绪的时间告诉事件循环, 事件循环利用超时时间这个参数"阻塞"在
poll上, 从而把时间事件和其他事件统一起来. - 在pingora里, 维护时间事件的是B树, 后台有专门一个检查线程. 检查线程每10毫秒会取出最近的
Notify, 判断事件触发的时间, 唤醒所有"阻塞"在这里的任务.
2. 超时事件
2.1 Tokio的超时事件
pub struct Timeout<T> {
value: T,
delay: Sleep,
}
impl<T> Future for Timeout<T> {
fn poll(self: Pin<&mut Self>...) -> {
// 推动业务任务
if let Poll::Ready(v) = me.value.poll(cx) {
return Poll::Ready(Ok(v));
}
// 推动休眠任务
match delay.poll(cx) {
Poll::Ready(()) => Poll::Ready(Err(Elapsed::new())),
Poll::Pending => Poll::Pending,
}
}
}
tokio里的超时事件Timeout是利用休眠事件Sleep实现的, 第一次调用poll(通常是await)时, 业务任务value和休眠任务delay被"同时"启动.
这两个任务中有任何一个完成, poll就会再次被调用. 如果就绪的是业务任务, 那返回最终结果; 如果就绪的是休眠任务, 返回超时错误. 到此, Timeout执行完毕, 会被丢弃.
2.2 Pingora的超时事件
pub struct Timeout<T, F> {
value: T,
delay: Option<Future>,
callback: ToTimeout
}
impl<T, F> Future for Timeout<T, F> {
fn poll(self: Pin<&mut Self>...) -> {
if let Poll::Ready(v) = me.value.poll(cx) {
return Poll::Ready(Ok(v));
}
// 惰性创建休眠任务
let delay = me.delay.
get_or_insert_with(|| Box::pin(me.callback.timeout()));
match delay.as_mut().poll(cx) {
Poll::Pending => Poll::Pending,
Poll::Ready(()) => Poll::Ready(Err(Elapsed {})),
}
}
}
pingora里的超时任务和上面的有两个区别, 一是休眠任务delay是惰性创建的, 在实际调用poll时才创建. 二是休眠任务是调用callback的timeout()方法创建的.
这里的dealy和callback就相对于是糊的胶水层, 使得pingora既可以支持tokio原生的超时事件TokioTimeout, 也可以是自定义的超时事件FastTimeout.
2.3 TokioTimeout超时事件
pub struct TokioTimeout(Duration);
fn timeout(&self) -> BoxFuture<'static, ()> {
Box::pin(tokio_sleep(self.0))
}
TokioTimout内部调用了tokio的sleep函数, 这个类型的超时事件是交给tokio里的时间轮管理的.
2.4 FastTimeout超时事件
pub struct FastTimeout(Duration);
fn timeout(&self) -> BoxFuture<'static, ()> {
Box::pin(TIMER_MANAGER.register_timer(self.0).poll())
}
FastTimeout会由TIMER_MANAGER管理, 放到10毫秒跨度的槽位里, 然后后台线程会周期性检查有没有有到时间的槽位, 如果就唤醒里面所有的事件.
3. Pingora时间事件管理
3.1 事件管理TimerManager
pub struct TimerManager {
timers: ThreadLocal<RwLock<BTreeMap<Time, Timer>>>,
zero: Instant,
}
static TIMER_MANAGER: Lazy<Arc<TimerManager>> = Lazy::new(|| {
let tm = Arc::new(TimerManager::new());
// 启动后台检查线程
check_clock_thread(&tm);
tm
});
管理时间事件的数据结构是TimerManager, 这里的timers就是存储10毫秒槽位的地方. 由于是ThreadLocal类型的, 所以每个线程里都自己有一份.
虽然timers是线程隔离的, 但还有下面要讲到的后台检查线程, 这个线程也会对时间事件进行读写, 所以这里加了一把RwLock. 并不是完全无锁的, 但在粒度上确实是小了.
3.2 后台检查线程
fn check_clock_thread(tm: &Arc<TimerManager>) {
std::thread::Builder::new()
.spawn(|| TIMER_MANAGER.clock_thread())
.unwrap();
}
创建的TimerManager的时候, 会创建后台线程, 线程要执行的方法是check_clock_thread.
pub(crate) fn clock_thread(&self) {
loop {
// 周期执行, 间隔10毫秒
std::thread::sleep(RESOLUTION_DURATION);
// 遍历不同所有线程里的timer
for thread_timer in self.timers.iter() {
loop {
...
// 已经到触发时间槽位
let timer = timers.remove(&k);
timer.unwrap().fire();
}
}
}
}
check_clock_thread的逻辑并不复杂, sleep(10ms)大约每10毫秒执行一次. 时间事件维护在每个线程自己的的B树里, 而timers.iter()方法会遍历所有线程的里的B树.
然后在每个线程的时间事件树上, 找到已经到了触发时间的槽位, 调用Notify.notify_waiters()方法, 唤醒"阻塞"在这些槽位上的所有事件.
pingora自定义的超时事件由事件FastTimeout, 事件管理TimerManager, 后台线程check_clock_thread构成. 这三部分互相配合, 替代了tokio原生时间轮的位置.
4. 小结
在我自己的计算机上跑基准测试, 用cargo bench运行benchmark.rs, 但得到的数据并不那么"漂亮". 这可能是因为基准测试里的用例很"死板", 和实际情况有很大出入.
不过, 如何替换tokio的时间事件管理机制, pingora的做法为我们提供了思路. 在某些条件下, 如果有必要, 我们也可以尝试定制自己的时间管理机制, 达到特定场景下的优化.